Method
Left: S4MC pipeline follows a teacher–student setup for semi-supervised segmentation. Labeled images are fed to the student to generate a supervised loss term, while unlabeled images are fed to both teacher and student. A threshold is dynamically chosen based on the teacher network predictions and applied to the refined confidence. Right: proposed confidence refinement module uses neighboring pixels to adapt the per-class predictions. The class distribution of one pixel that passes the threshold for the red class (dog), and after refinement, does not, since the margin between that and the blue class (cat) is lower.
Abstract
We present a novel confidence refinement scheme that enhances pseudo-labels in semi-supervised semantic segmentation. Unlike current leading methods, which filter low-confidence teacher predictions in isolation, our approach leverages the strong spatial correlation of labels in segmentation maps by grouping neighboring pixels and considering their pseudo-labels collectively
As a result, our method utilizes a larger amount of unlabeled data during training while maintaining the quality of the pseudo-labels.
Through extensive experiments on standard benchmarks, we demonstrate that S4MC outperforms existing state-of-the-art semi-supervised learning approaches, offering a promising solution to reducing the cost of acquiring dense annotations.
Notably, S4MC achieves a remarkable 6.34 mIoU improvement over the prior state-of-the-art method on PASCAL VOC 12 with 92 annotated images. The code to reproduce our experiments is available at https://github.com/s4mcontext/s4mc.
Results
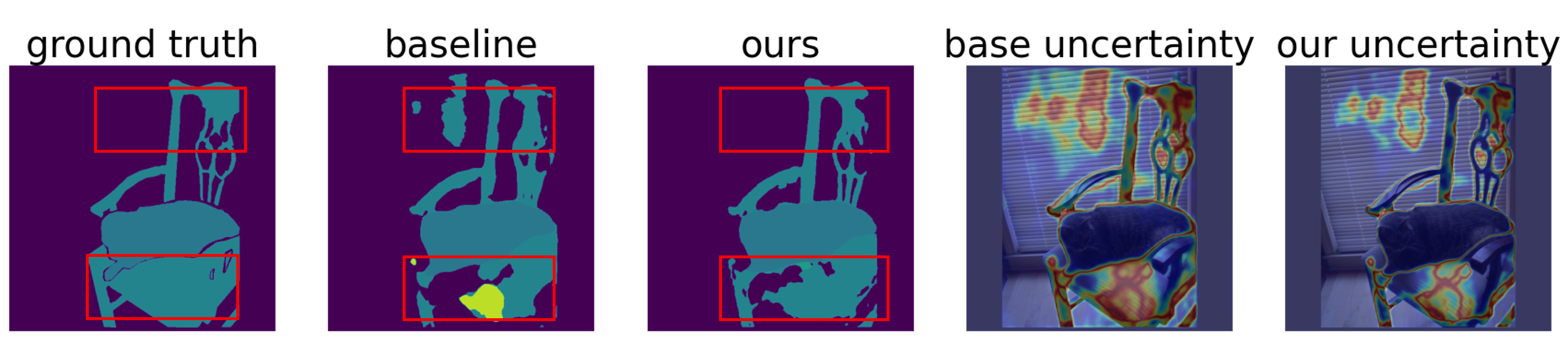

Example of refined confidence. The outputs of two trained models and the annotated ground truth.
Ours: The outputs of a model trained as explained in the method.
Baseline: The outputs of a model with the same training scheme apart from the usage of contextual information
Left to right: The ground truth labels from the dataset, the predictions of the baseline model, the predictions of our model, a heat map of class entropy of the predictions of the baseline model, and a heat map of class entropy of the predictions of our model.
Heat map: The original image with color markings from blue to red, from lower to higher values of entropy respectively. The baseline model predicts pixels as unassociated with classes of adjacent pixels and classes that do not occur in the image. The baseline predictions generally have higher entropy values, i.e., lower confidence values.
